sviridovt
-
Posts
340 -
Joined
-
Last visited
-
Days Won
81












About sviridovt

Recent Profile Visitors
5193 profile views


sviridovt's Achievements
")





-
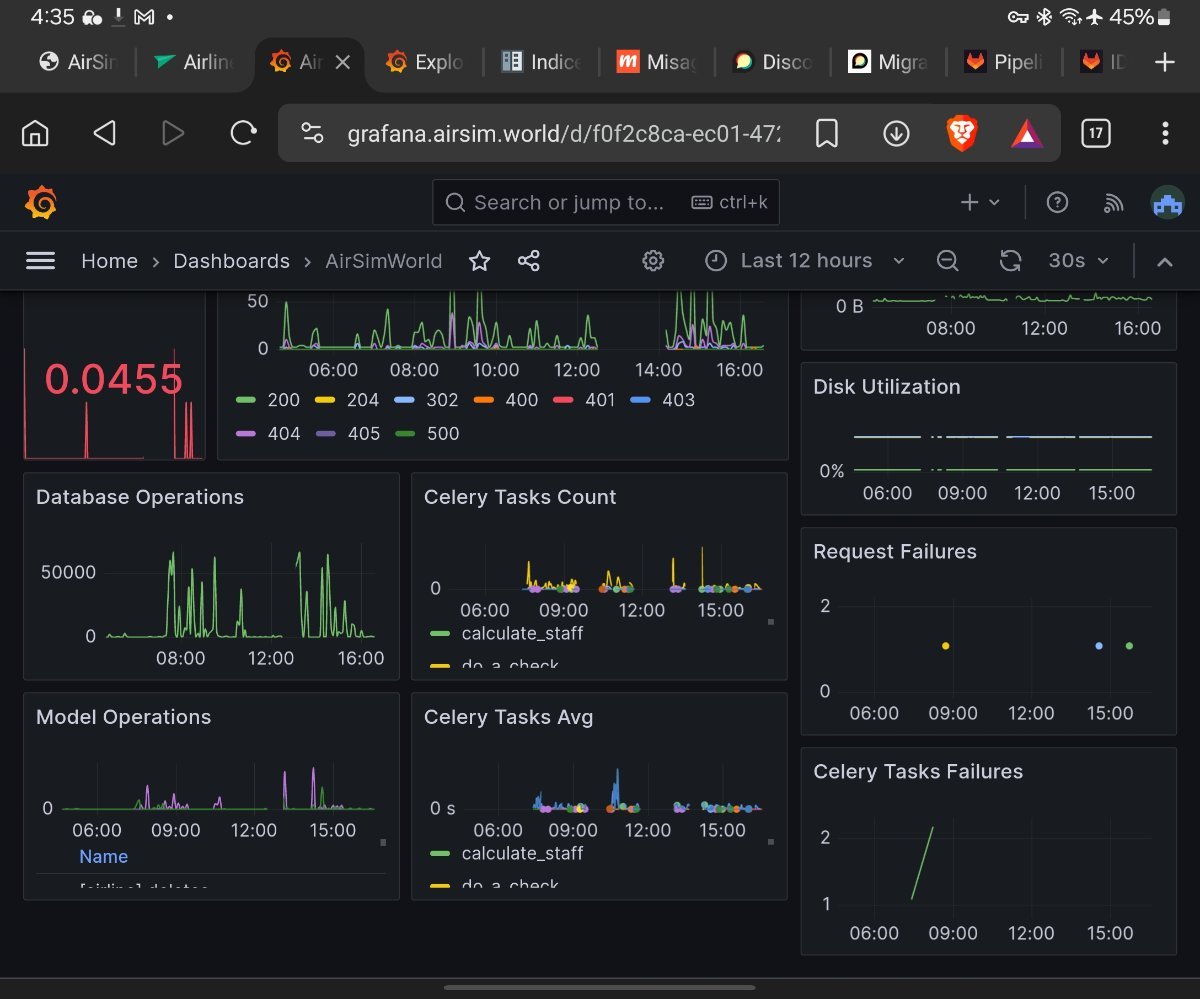
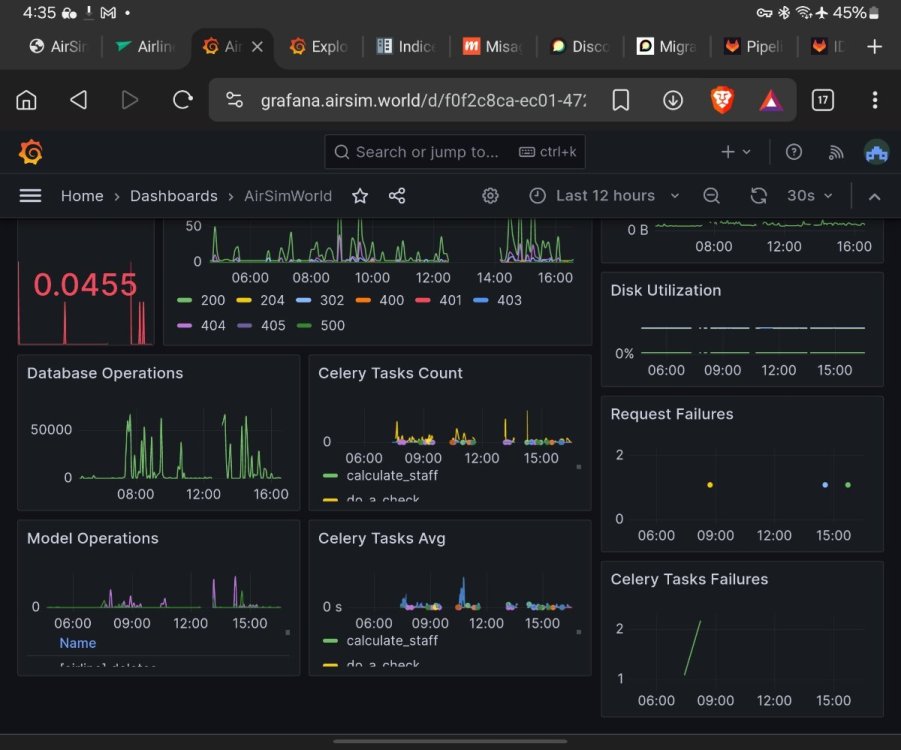
I have accelerated World C I to 15 minute days. I apologize for the issues regarding event manager stopping, I have deployed a patch to automatically run a health check and restart it, it seems to be working and restarting as expected. Still need to root cause the issue but hopefully this should act as a fix for now, will also keep it for the future as it seems to be a common issue. Attaching the screenshot of the dashboard for reference.
-

Who does Aurora International think they are?!
sviridovt replied to Freedom Airways INC.'s topic in General Discussion
I don't know, but locking this thread for now. On the bright side I was able to deploy a health check script that restarts event manager automatically and it seems to be working. I will check it after my flight and if it works will speed up world C I (not a permanent fix, but it's a fix). -
Hi! You cannot add stopovers in countries other than your own unless you're in Arcade world, which does not have political restrictions
-
Who does Aurora International think they are?!
sviridovt replied to Freedom Airways INC.'s topic in General Discussion
I dont have a problem with yall sharing accounts, though ultimately I will hold the account as a whole responsible for any issues, so its at your own risk. -
Who does Aurora International think they are?!
sviridovt replied to Freedom Airways INC.'s topic in General Discussion
Hi! What is going on here? A couple of things, 1. Can we please tame the rhetoric and keep the discussion civil. I won't lock the thread but consider this a warning 2. Aurora is not and has never been a mod in the game or the forum and does not have power to remove anyone as a leader of alliance in game (unless they are the founding member). As for Star Alliance, I can see that he is an alliance moderator, with @Sky Global Holdings as the owner. I generally try to stay away from alliance drama and so leave it up to @Sky Global Holdings to deal with regarding moderatorships in alliances. 3. I didn't read the entire thread (it's a handful, lots of accusations flying around), but if anyone believes there is any other issues requiring moderator intervention, either in game or the forum feel free to PM me and I will deal with it. Thanks! -
The issue is that the event manager keeps stopping after a few hours. I am on a work trip so have limited time but will take a look this weekend.
-
There is an issue going on right now with background tasks post update. I am on a work trip so my time is very limited to look at it, hence I've just been restarting it manually. I do apologize for the inconvenience.
-
Ill take a look wjen I get back from my work trip
-
This seems to be an issue with your browser. Try to press ctrl + shift +r to reload the cache. If that does not work, can you open the developer options (whrn you right click) and share any errors that might show up there. Thanks!
-
My Flights Arent getting passengers
sviridovt replied to Sky Global Holdings's topic in General Discussion
Ive been restarting celery processir as I see it going down. Have wirk trip this week so no ti.e to root cause, I deployed a little script that should hopefully restart it automatically until I have time to look it (though untested, so will check if it will work) -
How to delete a class in configuration?
sviridovt replied to rohithbala's topic in General Discussion
It looks like this configuration is edit locked since it's in use on a plane. For that case you would need to create a new configuration and change the plane over to that one (since you can't change a configuration that's in use). For configurations that are not edit locked you would see a small x that will allow you to delete a class from a plane. I don't like this page, it's not great UI and it has some issues (namely it spams the backend with every edit), it is high on my list of things to kill in my UI redesign. -
The next update isnt necessary the folloe update, its mors on bucket list and is not necessarily the highest on my priority list :p . However I would not be willing to increase willingness to pay, this is for a few reasons: 1. The game is already too easy imo, this would only make it easier. 2. I had considered adding full inflation model into the sim some time ago, but opted against it as I dont want to add a chore to players constantly having to increase prices to account for inflation. Its not fun for the user. 3. I want to make the sim more about broader management, like fleet management staff, strategy etc and move away from having to make constant micro adjustments to flight prices. However to address your concerns, the fuel prices are currebtly adjusted for inflation, and the increases are as well. Yes, prices for fuel increase over time relative to willingness to pay, but that is also realistic and an issue airlines IRL have to deal with (hence airlines always looking to maximize fuel efficiency). In the future years the fuel increase does stop (I forget the exact year, I want to say 2030 ish), with the new model price will still fluctuate around that and in the old model it will be flat.
-
For that flight your airline would have to be based in either US or Mexico
-
There appears to be an increase in database operations tied to updating demand causing slower than usual updates. I am investigating though I am on a work trip thos week and hence my time might be limited.
-
Arcade still uses the old model, but does have inflation hence prices will slowly increase over time. The old system has a quirk whereby prices would only updare when flight updates, so flights with little action wont see increases. As part of the update all prices were recalculated, hence why you might notice increases even in worlds not using the new model.